
跳动的音符,婉转的节奏,悠扬的歌声……
音乐无疑是最能愉悦身心的方式之一,那么歌手的音调、音色是如何存储到手机中,又是如何通过喇叭播放出来的呢?
下面我将通过几篇博客阐述我对音频的理解及部分调试经验,本章主要介绍音频的的基础知识
信号分类
声音严格意义来讲应该被叫做声音信号,而在维基百科中对于信号的定义是表示消息的物理量,这样就很好理解了声音信号就是以声音为载体的一个物理量。而自然界中信号可以有如下的分类
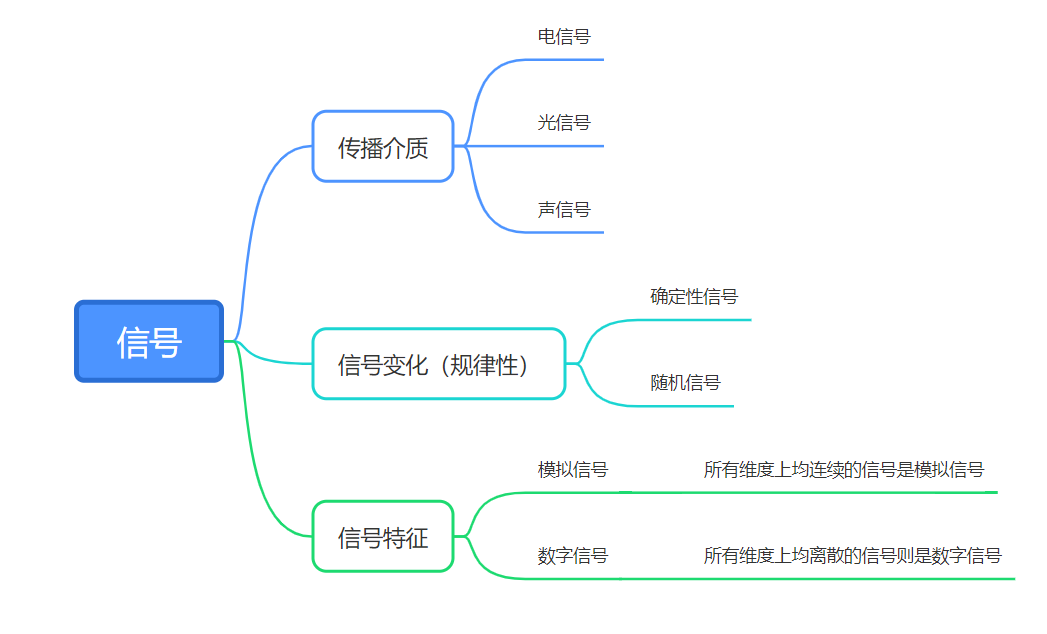
因此,按照信号变化分类声音信号属于随机信号;按照信号特征分类声音信号属于模拟信号
模数转换
上一部分了解到声音是模拟信号,而对于计算机来讲其只能处理数字信号即0和1,所以必须需要将声音模拟信号转换成数字信号,而这个过程叫做模数转换(Analog Digital Conversion),相应的完成该功能的硬件单元就叫做模数转换器(ADC)
完成该过程需要三部曲分别是:采样、量化、编码,整体过程如下图:
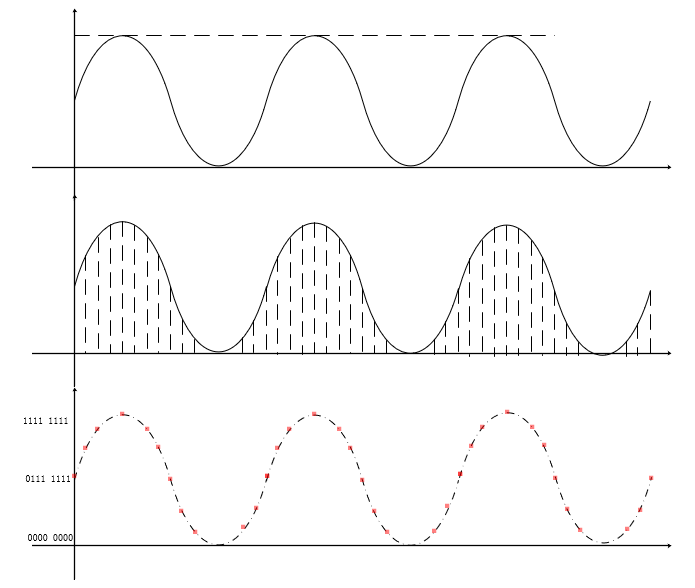
采样
重要参数:采样率
- 定义:在时间轴上对信号进行离散化
- 原理:按照一定的频率对模拟信号的瞬时时刻进行样本采集
其实采样作用通俗理解就是是采集样本。由于模拟信号是连续的,理论上我们需要采集无数个点才能完整的还原该信号,但是一来无穷的概念是不可能满足的,二来我们其实并不需要这么高的采样率。我们听觉是有延迟的就和视频帧不停的刷新欺骗我们的眼睛是画面连续的是一个道理。
所以采样率越高,声音的还原就越真实越自然,人对频率的识别范围是 20HZ - 22000HZ, 如果每秒钟能对声音做 22000 个采样, 回放时就足可以满足人耳的需求. 所以 22050 的采样频率是常用的, 44100已是CD音质, 超过48000的采样对人耳已经没有意义。这和电影的每秒 24 帧图片的道理差不多。
量化
相关参数:采样位数
定义:在幅度轴上对信号进行数字化
原理:对采样点的幅度赋予具体的数值,该数值由n位二进制表征(n = 8 / 16 / 32)
采样位数越高说明划分的等级越精细。较低的采样位数损失精度,较高的采样位数可能造成软硬件资源的浪费
小常识:标准CD音乐的质量就是16bit、44.1KHz采样
编码
定义:按照一定的格式记录 采样 和 量化 后的数据。后续会对部分格式的存储格式进行分析
编码分类
波形编码
- 定义:不利用生成音频信号的任何参数,直接将 时间域信号 变换为 数字代码,使重构的语音波形尽可能地与原始语音信号的 波形形状 保持一致。
- 原理:在 时间轴 上对模拟语音信号按一定的速率抽样,然后将幅度样本分层量化,并用代码表示。
参数编码
从语音 波形信号 中提取生成语音的参数,使用这些参数通过语音生成模型重构出语音,使重构的语音信号尽可能地保持原始语音信号的语意。也就是说,参数编码是把语音信号产生的数字模型作为基础,然后求出数字模型的模型参数,再按照这些参数还原数字模型,进而合成语音。
混合编码
混合编码是指同时使用两种或两种以上的编码方法进行编码。这种编码方法克服了波形编码和参数编码的弱点,并结合了波形编码高质量和参数编码的低编码率,能够取得比较好的效果。
WAV编码(波形编码)
WAV是编码的一种实现方式(其实它有非常多实现方式,但都是不会进行压缩操作)。就是在源 PCM 数据格式的前面加上44个字节。分别用来描述 PCM 的采样率、声道数、数据格式等信息。
MP3编码
MP3编码具有不错的压缩比,而且听感也接近于WAV文件,当然在不同的环境下,应该调整合适的参数来达到更好的效果。
AAC编码
AAC是目前比较热门的有损压缩编码技术,并且衍生了LC-AAC、HE-AAC、HE-AAC v2 三种主要编码格式。
LC-AAC:是比较传统的AAC,主要应用于中高码率的场景编码(>= 80Kbit/s)
HE-AAC: 主要应用于低码率场景的编码(<= 48Kbit/s)
Ogg编码(有损)
Ogg编码是一种非常有潜力的编码,在各种码率下都有比较优秀的表现。尤其在低码率场景下。Ogg除了音质好之外,Ogg的编码算法也是非常出色。可以用更小的码率达到更好的音质。128Kbit/s的Ogg比192Kbit/s甚至更高码率的MP3更优质.但目前由软件还是硬件支持问题,都没法达到与MP3的使用广度.
音频参数
一段悠扬的音乐经过采样、量化、编码就保存数字信号文件,而我们最终的目的一定不是只存成文件而是通过文件形式传播让更多人听到该音乐,因此一定存在DA转换,即还原数字信号为模拟信号的过程。那么在整个过程中有哪些参数表征了音频重要的信息呢?
不仅限于webrtc、ffmpeg、libmad等等音频编解码库,对于所有编解码器和codec来讲,音频源数据的三个参数至关重要:声道channel、采样率sampleRate、采样位数sampleBit。这三个参数之所以重要是因为有这几个参数就可以准确的知道一个裸的音频数据(PCM)的全部信息了。
声道
声道是指音频文件在录制时音源的数量位置和播放时相应的扬声器的数量(百度百科)。所以可想而知,其他参数相同的情况下,声道数越多定位越精准,同样所需扬声器和功放组件越多。
- 单声道(mono)
- 双声道(stereo 立体声):左声道 + 右声道,低音不分离,应用于音乐播放较多
- 2.1声道 :左声道 + 右声道, 低音分离
- 5.1声道 :左声道 + 右声道 + 低音声道 + 中央声道 + 左环绕 + 右环绕,应用于类传统影院和家庭影院中
- 7.1声道 :左声道 + 右声道 + 低音声道 + 中央声道 + 左环绕 + 右环绕 + 左后环 + 右后环,常见的包括:Dolby Surround 7.1杜比7.1环绕声
采样率
采样率可以理解为采集样本的速率(故也可以称为采样速度或者采样频率),它定义了每秒从连续信号中提取并组成离散信号的采样个数,它用赫兹(Hz)来表示。
例如:采样率为44100,意味着每秒钟对连续的声音信号采集44100次,同样对应得到的数字信号每秒的样本数量(具体可以参考采样过程)
采样位数
采样位数就是指某一瞬时时刻,量化声音大小(精细程度)的计量单位
- 8bit ( 1Byte ) 对应0~255,将振幅划分为256个等级
- 16bit (2Byte) 对应0~65535,将振幅划分为65536个等级
样本格式
样本组合形式
- 交错模式:每个声道的样本数据交错存储排布
- 平面模式:每个声道的样本数据分开存储
下面以stereo模式进行图示解释(C代表Channel):
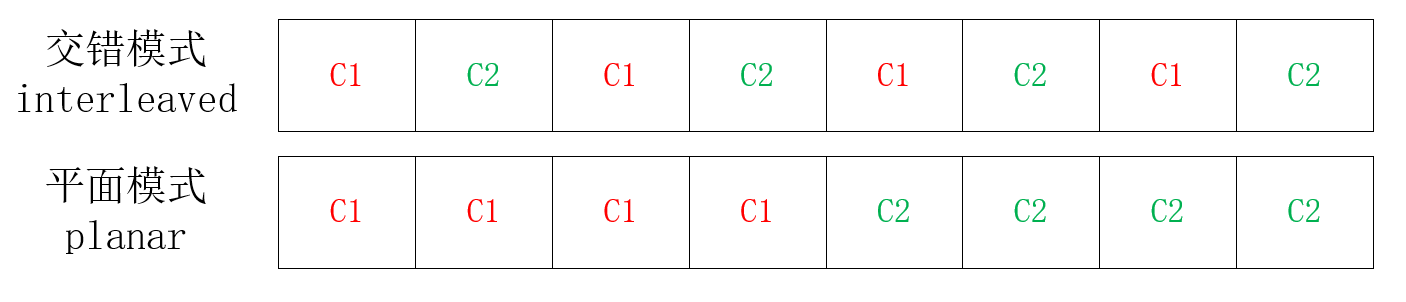
FFmpeg 样本组织形式介绍
- Packed格式,frame.data[0]包含所有的音频数据。
- Planar格式,frame.data[i]表示第i个声道的数据(假设声道0是第一个)
FFmpeg 主要样本格式
1 | enum AVSampleFormat { |
说明:以P为结尾的是planar结构;Planar模式是FFmpeg内部存储模式,我们实际使用的音频文件都是Packed模式的。
比特率
比特率指的是单位时间播放连续的媒体如压缩后的音频或视频的比特数量,在这个意义上讲,它相当于术语数字带宽消耗量,或吞吐量。单位bps / Kbps(bit per second)这里是bit而不是Byte(1Byte = 8bit)
虽然经常作为“速度”的参考,比特率并不测量“‘距离’/时间”,而是被传输或者被处理的“‘二进制码数量’/时间”,所以应该把它和传播速度区分开来,传播速度依赖于传输的介质并且有通常的物理意义。(来自维基百科)
参数关系
对于PCM裸数据: 文件时长 ≈(文件总大小 - 头信息)/ (采样率 * 采样位数 * 通道数 / 8) [也就是比特率]