defget_data(): job_information = [] url_lists = get_link() for i,url inenumerate(url_lists): datalist=[] header = { "User-Agent": "Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/88.0.4324.150Safari/537.36" } response = requests.get(url, headers=header) try: html = response.content.decode("gbk") data = etree.HTML(html) link = url datalist.append(link) #存入岗位链接 title = data.xpath(r'//div[@class="cn"]/h1/@title')[0] datalist.append(title) #存入岗位名称 salary = data.xpath(r'//div[@class="cn"]/strong/text()')[0] datalist.append(salary) information = data.xpath(r'//p[@class="msg ltype"]/@title')[0] information = re.sub(r"\s+", "", information) # 去除空白格 experience = information.split("|")[1] datalist.append(experience) education = information.split("|")[2] datalist.append(education) num = information.split("|")[3] datalist.append(num) place = data.xpath(r'//p[@class="fp"]/text()')[0] datalist.append(place) treatment = data.xpath(r'//span[@class="sp4"]/text()') treatment = " ".join(treatment) datalist.append(treatment) print("-----第{}条------".format(i)) job_information.append(datalist) except Exception as e: print("-----第{}条出错,原因是{}------".format(i,e)) continue #print(job_information) #测试 return job_information
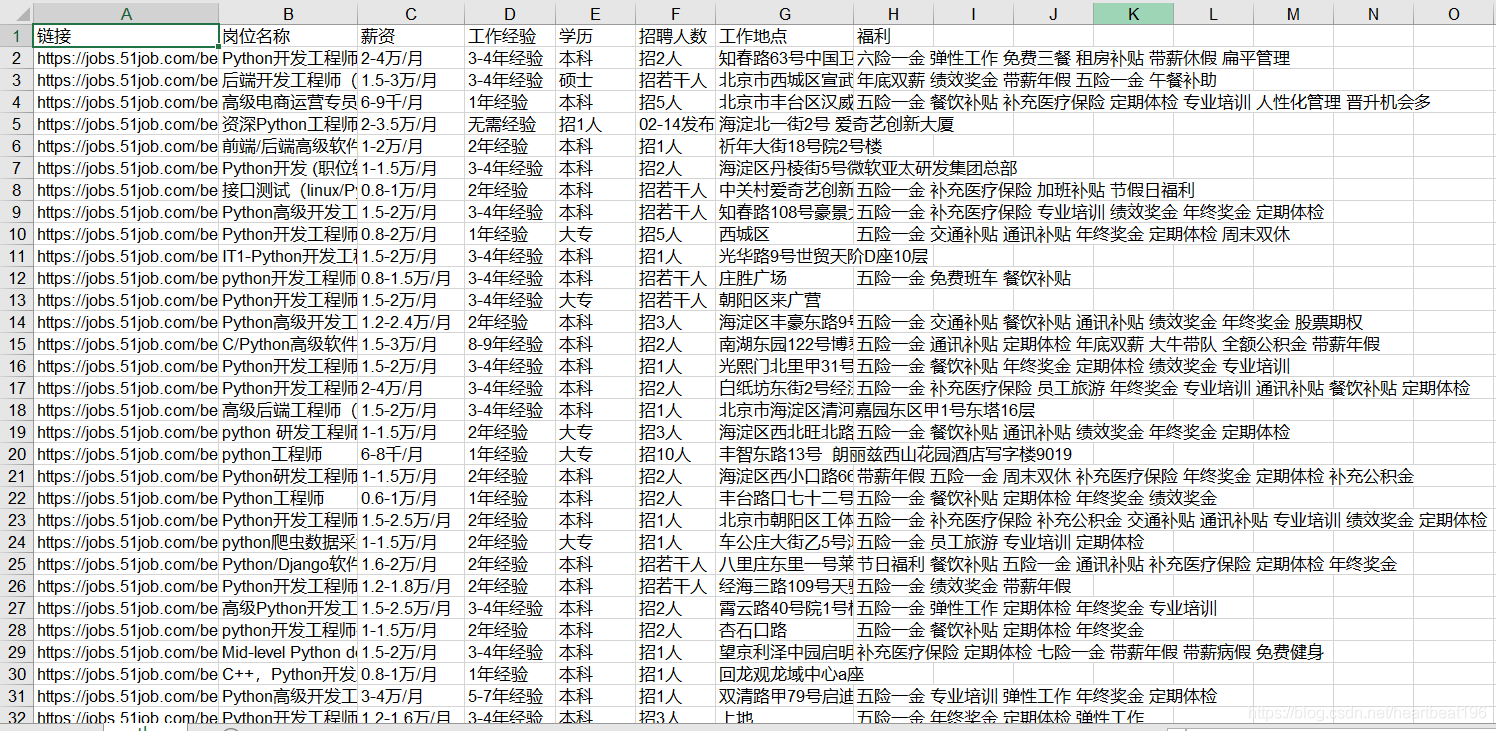
数据存储
Excel本地保存
1 2 3 4 5 6 7 8 9 10
defsave_data_excel(datalist): workbook = xlwt.Workbook(encoding="gbk", style_compression=0) worksheet = workbook.add_sheet("python") col = ["链接", "岗位名称", "薪资", "工作经验", "学历", "招聘人数", "工作地点", "福利"] for i inrange(0, 8): worksheet.write(0, i, col[i]) for i inrange(len(datalist)): for j inrange(0, 8): worksheet.write(i+1,j,datalist[i][j]) workbook.save("北京-python工作.xls")
Excel数据保存结果展示
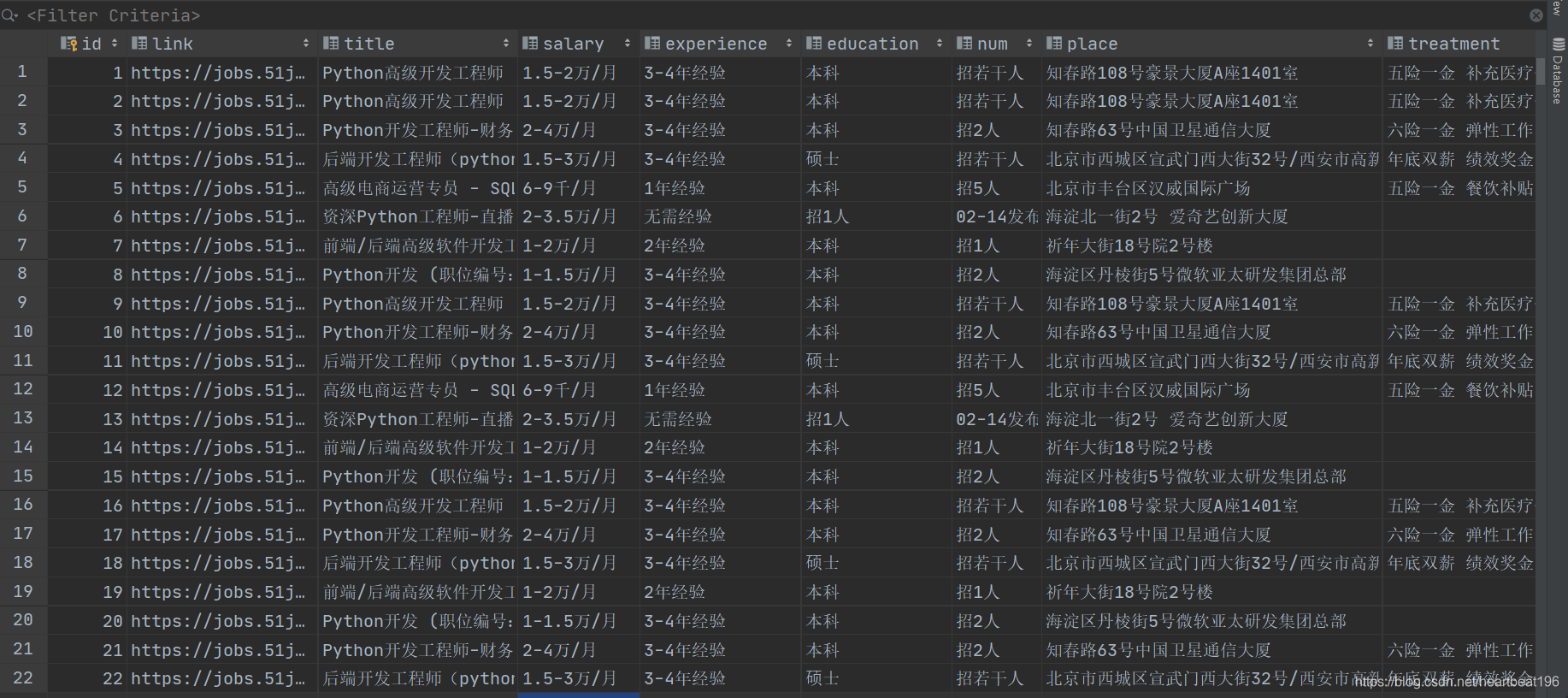
sqlite数据库保存
在此部分只写了数据库保存的工作,数据库的初始化创建需函数sql_init需要添加即可使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
defsave_data_sql(datalist,dbpath): sql_init(dbpath) conn = sqlite3.connect(dbpath) cur = conn.cursor() for data in datalist: for index inrange(len(data)): data[index] = '"' + data[index] + '"' sql = ''' insert into job_information( link,title,salary,experience,education,num,place,treatment) values(%s)'''%",".join(data) #print(sql) #测试sql语句是否正确 cur.execute(sql) conn.commit() cur.close() conn.close()