引语
在爬虫各个应用场景下,数据解析为其中重要的一环。而在数据解析中,BeautifulSoup、Xpath以及正则表达式等多种方法均为利器,在实际应用中根据不同场景选择不同的方法是最高效的,但是对各个方法的掌握程度要求很高。事实上,精通一种方法就已经满足需要了,再此基础之上,用辅助工具帮助理解提高效率。
本文将提供给“爬虫大师们”使用xpath方法的辅助工具XPath Helper插件。
XPath Helper简介
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。
XPath Helper是一款专用于chrome内核浏览器的实用型爬虫网页解析工具。XPath Helper插件功能强劲,支持进行XPath查询功能。XPath Help插件可以帮助用户在各类网站上通过按shift键选择想要查看的页面元素来提取查询其代码,同时还支持用户对查询出来的代码进行编辑,而编辑出的结果将立即显示在旁边的结果框中。
XPath Helper安装方法
- 根据下面的链接将文件下载到本地。
链接:https://pan.baidu.com/s/18_Ws5qjHW9skhE1cb1jtYA
提取码:x0no - 下载完成后,将文件的后缀名改为“.zip”,并进行解压。
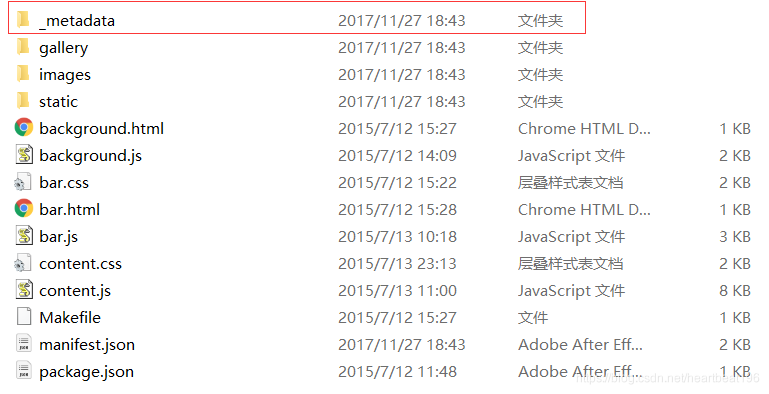
- 解压之后有两个文件,将文件名为“2.0.2_0.crx”后缀名改为“.zip”,并对其进行二次解压。
==至此,所有弹出的提示语句全部选择 是== - 二次解压完成,获得如下图所示的文件夹。如果红色框内文件夹如图所示,将“_metadata”改为“metadata”。如果默认就是“metadata”则不需要做任何操作。
- 进入自己对应的浏览器。在此,我以Google浏览器为基础操作。
**点击谷歌右上角的三个点的按钮
选择更多工具——>选择扩展程序
进入,打开开发者模式,加载已解压的扩展程序,选择相应的已解压的文件,确认!
重启浏览器,确认可以正常使用**
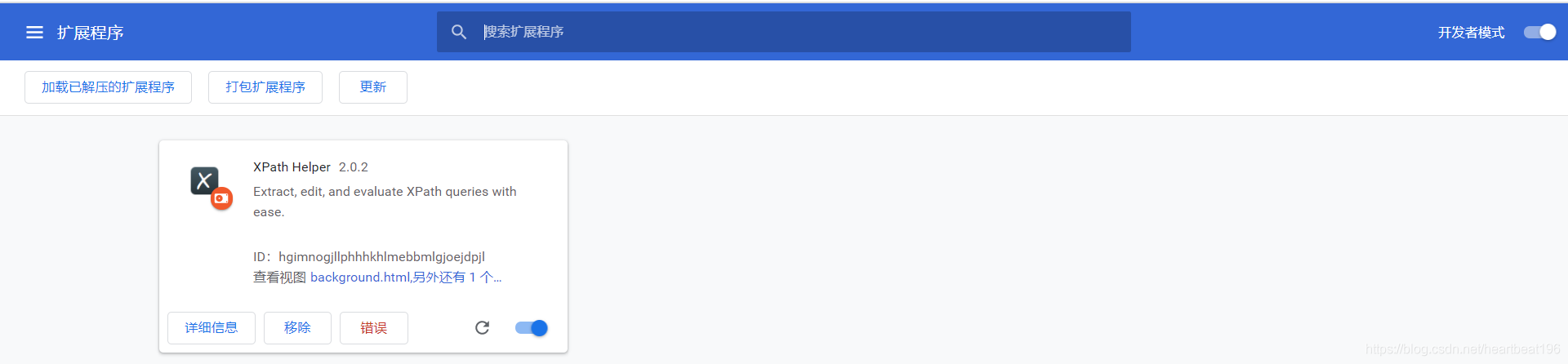
- 如下图表示创建成功。
XPath Helper简单使用方法
作用
- 获取页面元素的xpath地址。
- 验证用户自己写的xpath地址是否正确。
使用方法
- 打开/关闭XPath Helper快捷键:Ctrl+Shift+x
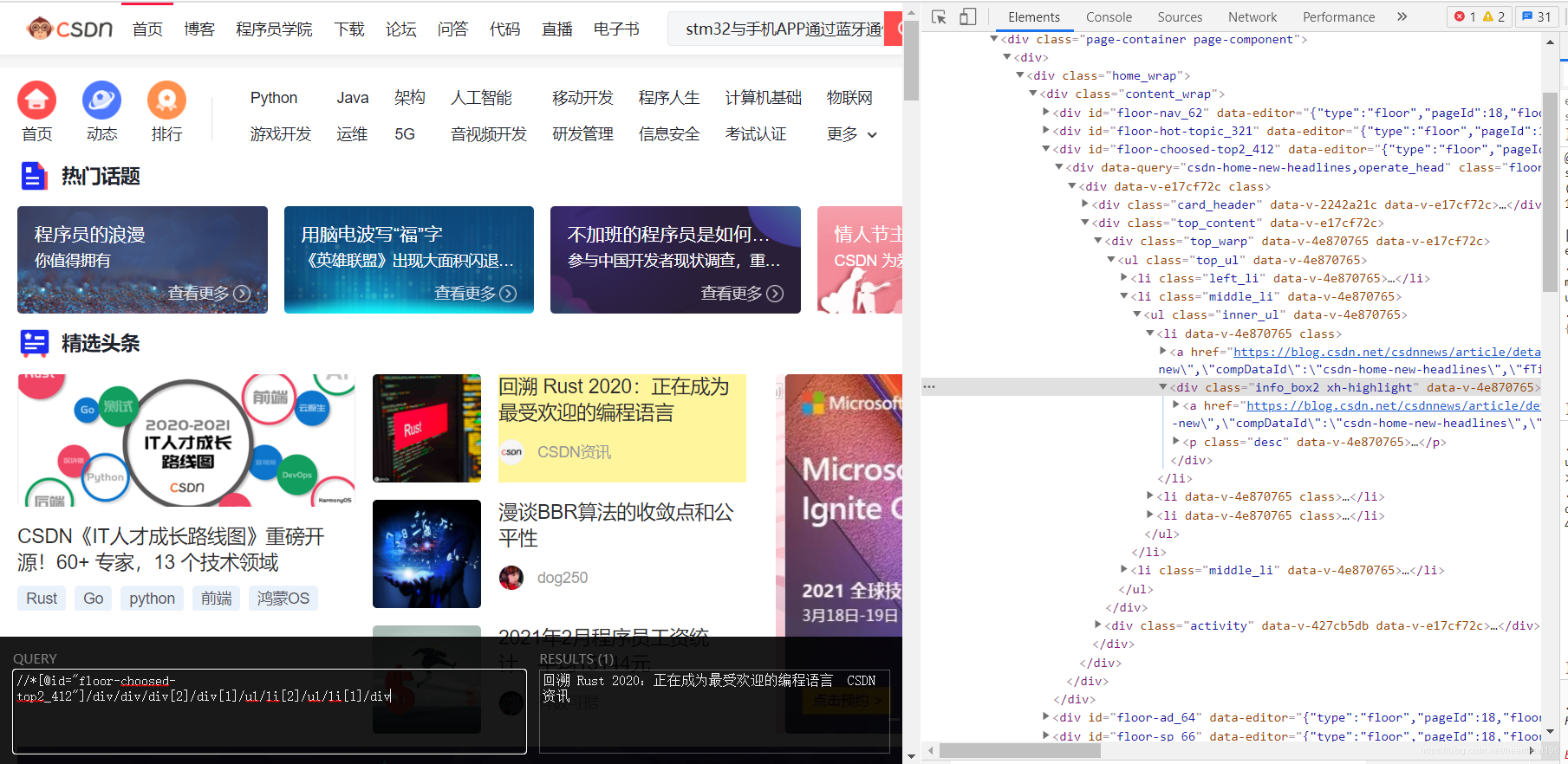
- 打开Xpath Helper后的结果如下图所示

- 打开该插件的情况下,按住Shift在页面内进行移动,鼠标所经过之处会有黄色方框显示,下图为在CSDN首页,选中标题引导框的结果。左侧的query框内即为选中内容的xpath地址。
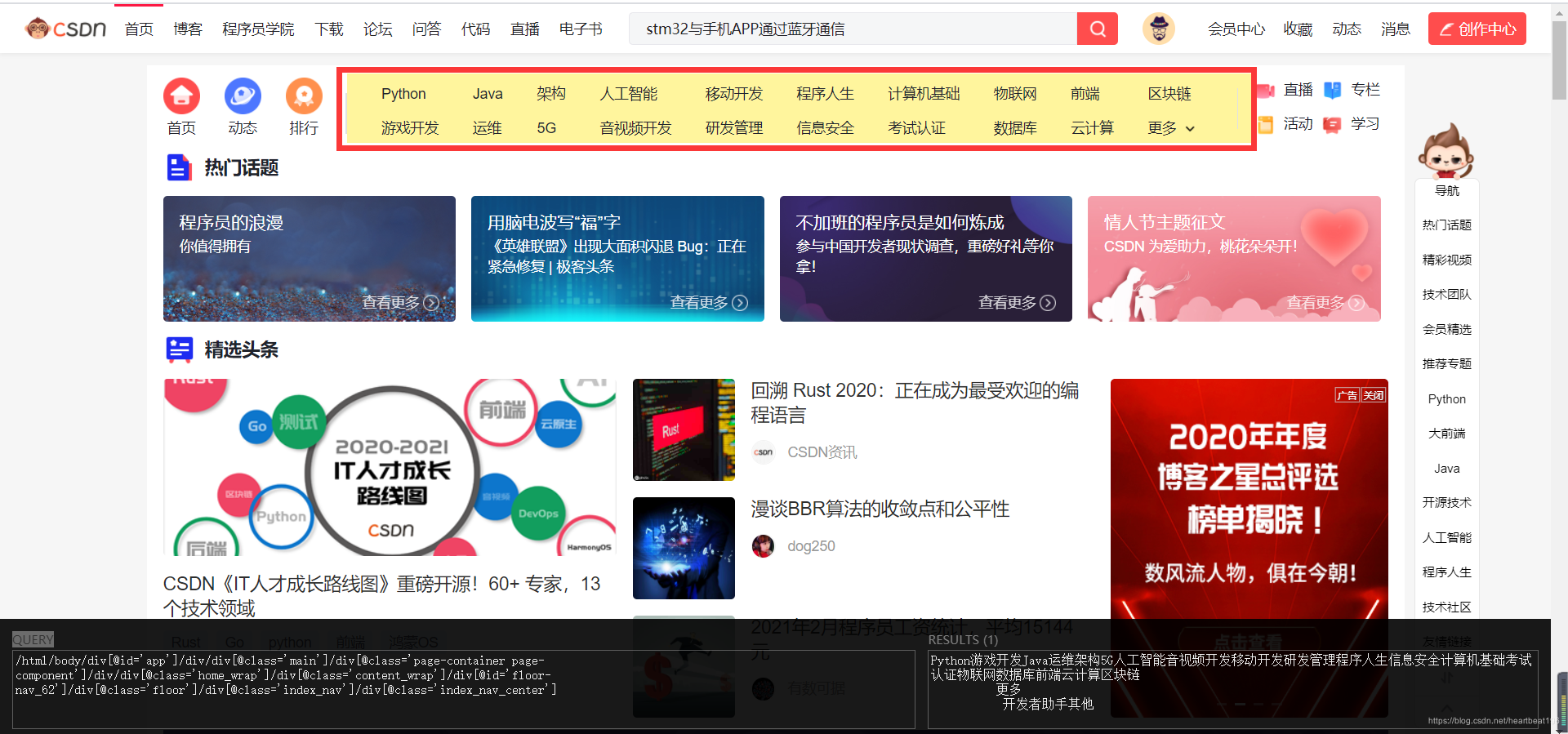
- 如果作为验证的方法,在query框内写入自己写入xpath地址,看result框内是否是自己想要抓取的元素,如果不正确,可以实时在query内进行修改,直至获得正确xpath地址。