
概念
局部性原理
在大多数程序运行过程中,CPU对于内存的访问会表现出明显的倾向性,具体体现在两个方面:
- 时间局部性:时间维度看,被引用过的内存位置,不远的将来将大概率再次被访问
- 空间局部性:空间维度看,被引用过的内存位置,不远的将来它附近的内存位置将大概率被访问
缓存块
linux查看缓存信息命令:getconf -a | grep CACHE
概念
根据cache的作用可知cache当中存储的是主存的副本,其必须是要和主存进行数据交换的。基于效率角度考量,根据程序局部性原理,CPU是不会按照一个字节一个字节进行数据的加载至缓存中,而是按块进行加载,而这每一块就叫做cache line,也称缓存块
- 缓存块(cache line),管理缓存结构的最小存储单元,目前常用的是64Bytes(内存系统支持Burst读/写效率更高)
结构

- 标识位V:表示该缓存块是否有效
- 标识位M:表示这个缓存块是否被修改,也就是脏位
- Tag:和内存块匹配的标识
- Data:缓存数据内容
需要注意的是 V、M、Tag这几位是由硬件门电路实现的,并不占缓存空间。而Data才是真正的数据部分
缓存命中/缺失
- Cache Hit:访存时,如果所需要的数据在cache中则成为缓存命中
- Cache Miss:访存时,如果所需要的数据不在cache中则成为缓存缺失
缓存映射方式
视频链接:click here
从概念上讲,高速缓存是一个相联存储器(Associative Memory)。硬件电路实现方式及映射策略的不同,缓存的映射方式分为三种:
- 全相连映射:主存块可以映射到任一缓存行(缓存只有一个组,所有的内存块都放在这一个组的不同路上)
- 直接相连映射:主存块只能映射到固定的缓存行(缓存只有一个路,一个内存块只能放置在特定的组上)
- 组组相连映射:主存块只能映射到固定的缓存组,组内任一缓存行(缓存同时由多个组和多个路)
片外的高速缓存通常是直接映射的,因为组相联需要更宽的接口,可以取得多个标签,并发匹配
特点
| 组织方式 | 特点 | 应用场景 |
|---|---|---|
| 全相联映射 | cache利用率高 块冲突低 淘汰算法复杂 |
小容量cache |
| 直接相连映射 | cache利用率低 块冲突高 淘汰算法简单 |
大容量cache |
| 组相联映射 | cache利用率较高 块冲突率较低 硬件实现复杂 |
中等容量cache |
映射算法
- 全相联:cache行号 = random
- 直接相联:cache行号 = 内存块号 % cache行数
- 组相联:主存的数据块映射到Cache特定组的任意行,cache组号=主存块号 % cache组数
缓存块替换策略
随机法(RAND)
方法简单、易于实现,但命中率比较低。
先进先出算法(FIFO)
先进先出方法易于实现,命中率比随机法好些。
最近最久未使用算法(LRU,Least Recently Used)
可以比较好地遵循程序局部性原理
缓存写策略
write back 写回
将要写入的数据保留在高速缓存中,并进行标记(Dirty / Modified)。只有缓存块被替换的时候才会将数据写入主存
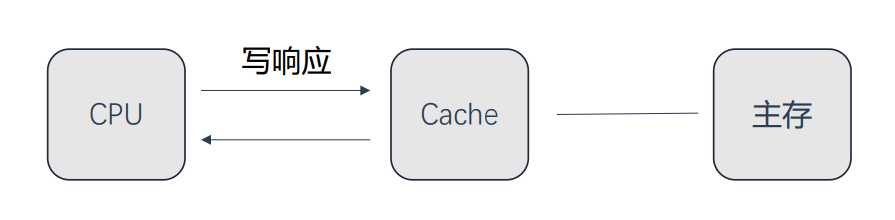
write through 写透/写穿/写直达
CPU总是将数据直接写到主内存中
note:如果等待写内存完成处理器的性能会急剧下降,通过写缓冲(Write Buffer)硬件可以弥补这一问题。将需要写入的数据存储在一个FIFO队列中(Write Buffer),由内存控制器进行写入操作
其它
由于效率原因,写更新和写不分配这两种策略在现实中比较少出现
CPU 之间的更新策略
当某个 CPU 的缓存中执行写操作,修改其中的某个值时,其他 CPU 的缓存所保有该数据副本的更新策略分为:写更新(Write Update)和写无效(Write Invalidate)。
写缓存时数据是否被加载
当前要写入的数据不在缓存中时,根据是否要先将数据加载到缓存中,写策略分为:写分配(Write Allocate)和写不分配(Not Write Allocate)。
缓存效率
衡量标准
两个参数的乘积:
- 高速缓存缺失率:cache miss / 被执行的指令次数
- 高速缓存缺失重填的开销:cpu流水线重新计算从主存取数到缓存中的时间
cache miss的原因?
《see mips run》对于以下缺失类型分别称为:第一次访问;抖动;替换
- 强制缺失。第一次将数据块读入到缓存所产生的缺失,也被称为冷缺失(cold miss),因为当发生缓存缺失时,缓存是空的(冷的);
- 冲突缺失。由于缓存的相连度有限导致的缺失(指在同一组内的缺失);
- 容量缺失。由于缓存大小有限导致的缺失(描述范围是整个缓存)
如何提高利用率?
- 软件
- 程序更小;
- 让程序经常执行的部分更小。对于一个程序错误处理/初始化代码等部分代码剥离出来,提高剩余程序的缓存命中率;
- 安排程序尽量不发生冲突缺失(抖动)
- 直到必须用到数据时才停止CPU。非阻塞读。取数操作执行完,继续执行不依赖该数据的代码(流水线乱序/分支指令等等)
- 多线程CPU
- 硬件
- (1)让高速缓存变的更大(代价)
- (1)增加缓存相连度(4路以上效果就不明显了,更高路相连缓存设计目的在于其它原因(降低功耗,不使用时关掉整路))
- (1)增加额外层次的高速缓存(L2 L3 cache)
- (2)增加带宽,cpu与主存物理位置更近(代价)
- (2)增加内存burst带宽(现在很少使用)
- (2)尽早地重启CPU
- (2)关键字优先
管理缓存
对于MIPS CPU,synci指令做了以下所有工作(用户特权级)
上电之后CPU的高速缓存阵列内容通常是随机的。引导软件负责初始化高速缓存,系统启动并正常运行后,只有三种情况CPU必须进行干预:
- DMA设备从内存取数据之前。如果是Write Back式写策略,需要将在高速缓存中未写入到主存的数据写入得到正确数据
- DMA设备写数据到内存之前。需要将高速缓存中对应的缓存行的标志位置Invalid(无效的)
- 写指令。当cpu自身写一部分指令到内存用于稍后执行时,首先需要保证指令写入到内存中,其次保证 I-Cache 中对应的指令无效
视频推荐: