
随着技术的不断进步,芯片制程和工艺有了极大的发展,相应的CPU的计算能力越来越强。作为程序员,我们希望有无线资源的快速存储器可以使用,但是快速存储器的成本非常高昂,因此访存变成了计算机系统的性能瓶颈。为了平衡cpu运行速度与访存速度之间的差异缓存被设计出来!
简介
缓冲存储器,简称缓存(cache),用于存储可能频繁访问的数据。
缓存结合了寄存器速度快和内存造价低的优点,因此通过缓存的设计使整个存储系统的性能接近寄存器,并且每字节的成本都接近内存,甚至是磁盘。
高速缓存的工作就是将内存中最近读写过的数据在高速缓存中保留一个备份,使这些数据能够快速地返回给CPU
硬件实现
本节内容大多取自极客时间,《编程高手必学的内存知识》海纳
缓存的组成单元是SRAM,而目前SRAM通常采用了6管式的存储电路
简单来讲,SRAM 存储单元的特点是使用 6 个晶体管来实现。其中两个 P 型 MOS 管和两个 N 型 MOS 管组成两个反相器用于存储信息。还有两个用于控制存储单元是否选通。6 管 SRAM 的结构比触发器简单,速度也比较快
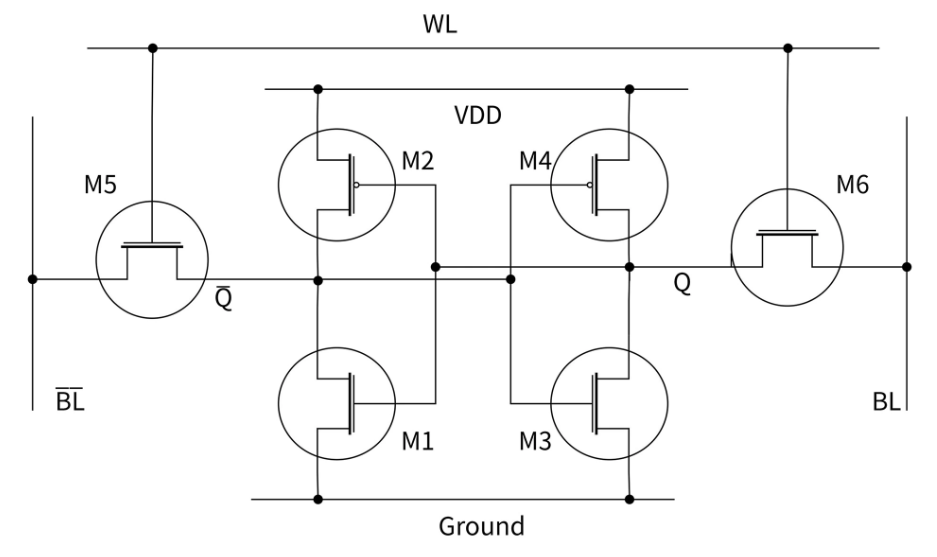
连接图
如下图所示,M1 和 M3 两个 MOS 管,是 N 沟道场效应管,在高电压时导通;而 M2 和 M4 这两个 MOS,则是 P 沟道场效应管,在低电压时导通。本质上,M1 和 M2 一起组成了一个非门,M3 和 M4 一起组成了另一个非门,这两个非门的输出互为对方的输入,这样,两个非门就组成了一种可以存储比特值的电路。
等效图
读写原理
当要读入SRAM数据时,字线 (Word Line, WL) 加高电平,使得每个基本单元的两个控制开关M5、M6导通,存储单元与位线 (Bit Line, BL) 连通。位线用于读取或写入基本单元的保存状态。
我们假定储存的内容为 1,即在 Q 处的电平为高。读取周期开始时,两条位线预先设成高电平,随后字线 WL 变成高电平,使得两个访问控制晶体管 M5 与 M6 导通。Q 的高电平使得晶体管 M1 导通,而 Q 反与 BL 反的预充值不同,使得 BL 反经由 M1 与 M5 放电而变成逻辑 0。在位线 BL 一侧,Q 反的低电平使得 M4 导通,再加上 M6 通路,位线就连接到 VDD 的高电压。
如果储存的内容为 0,相反的电路状态将会使 BL 反为 1,而 BL 为 0。这时,只需要 BL 与 BL 反有一个很小的电位差,读取的放大电路就会辨识出哪条位线是 1,哪条是 0。也就是说,当敏感度越高时,读取的速度就越快。
在写入周期开始时,把要写入的状态加载到位线。如果要写入 0,则设置 BL 反为 1 且 BL 为 0。随后字线 WL 加载为高电平,位线的状态被加载进 SRAM 的基本单元。
缓存基础
集成方式
- 分布式缓存:一个处理器对应一个缓存;
- 集中式缓存:多个处理器(核)共享一个内存;
- 混合式缓存:在 L3 采用集中式缓存,在 L1 和 L2 采用分布式缓存。
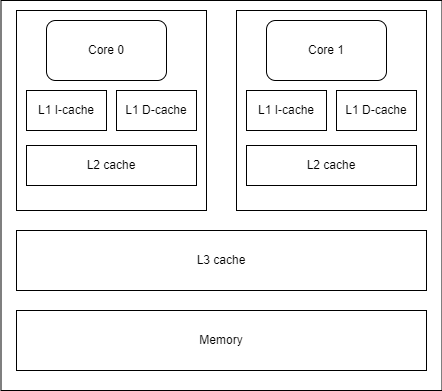
缓存结构
冯诺依曼架构:指令和数据混合存储在同一存储器
哈弗架构:指令和数据独立存储,分别放在程序存储器和数据存储器
在cache设计之初,cpu与内存之间只有一个cache。随着芯片工艺的提高,现代CPU通常采用二级/三级多级缓存结构。
- 一级缓存(L1 Cache):在Core内部,分为指令缓存(I-cache)和数据缓存(D-cache)(冯诺依曼架构)。容量通常在32~256KB,速度3 cycles
- 二级缓存(L2 Cache):具体芯片Core内外不同。容量256KB~3MB不等,速度11cycles(哈弗架构)
- 三级缓存(L3 Cache):在Core外部,所有CPU核心共享。容量更大,速度25cycles(哈弗架构)
Q&A
统一缓存: 指令和数据统一存放在一个缓存中
分离缓存: 指令和数据分别存放在不同缓存中
L1 采用分离缓存的原因?
- 流水线角度。可避免取指和执行时期的访存冲突。 在 CPU 内核中,取指和访存是由两个不同的硬件单元完成的。如果使用统一缓存,当 CPU 使用超前控制或流水线控制(并行执行)的控制方式时,会存在取指作和访存同时争用同一个缓存的情况,降低 CPU 运行效率
- cache行为角度。I-cache大多是顺序取指,指令只有读没有写;D-cache是取数据变化较大,数据可读可写,最重要的是冯诺依曼的结构是指令和数据分离,I和D在一起只有相互干扰
- 物理设计角度。一块cache,同时需要数据和指令的访问,端口上是很难实现的
L1分离缓存、L2统一缓存?
- 成本角度。L1 cache miss 性能损失与增加L2分离缓存的成本的平衡
- 物理设计角度。分离式设计会占用逻辑电路的面积与设计难度,对于L1这种size比较小的采用分离式设计可以承受,但是对于更大的Cache全采用分离设计,无疑设计难度和面积都会加大
- 效率角度。分离缓存不适用所有情况,对于指令和数据存放大小的需求不同,无法做到动态调节cache的大小,可能会有浪费
cache放在片内的优势?
- 片内缓存物理距离更短,片内缓存与取指令单元和取数据单元的物理距离更短,速度更快;
- 片内缓存不占用系统总线, 片内缓存使用独立的 CPU 片内总线,可以减轻系统总线的负担。
不需要cache的场景?
51单片机、cortex-M0(–M4)系列ARM处理器都没有cache
- 低功耗、低成本处理器并且工作频率不高(几十兆到几百兆)的处理器不需要,可能甚至不需要SRAM
- cache无法保证实时性,缓存缺失时向RAM加载数据的时间是不等的