
无论是计算机硬件还是软件,新的技术的出现的初衷一定是为了解决某项需求,而随之而来的可能会带来新的问题,无所谓解决就是了!
MESI带来的性能问题
从本质上来讲MESI协议解决的是数据的核间同步问题,但是严格遵守MESI协议一定又会带来新的问题。以下两种情况会再次带来性能问题:
- 更新Shared状态的Cache。当某个缓存行的状态是Shared时,CPU想要修改该缓存行的数据,一定会产生总线事件通知其它CPU将该缓存行副本状态置Invalid,当拥有该缓存行副本的CPU确认并回复它“Invalid acknowledgement”以后,它才能进行数据更新。
- 更新Invalid状态的Cache。当某个缓存行的状态是Invalid时,CPU想要修改该缓存行的数据,一定会产生总线事件从其它CPU甚至是主存中加载进最新数据,进而基于最新数据进行更新。
MESI协议优化
MESI协议以上两个痛点可以发现是由于事务串行化所带来的负面影响。所以解决这两个问题的关键就是使MESI协议的请求异步化,释放总线提高并行度。因而就有了在硬件上增加写缓存区和失效队列两种方法。
写缓冲 Store Buffer
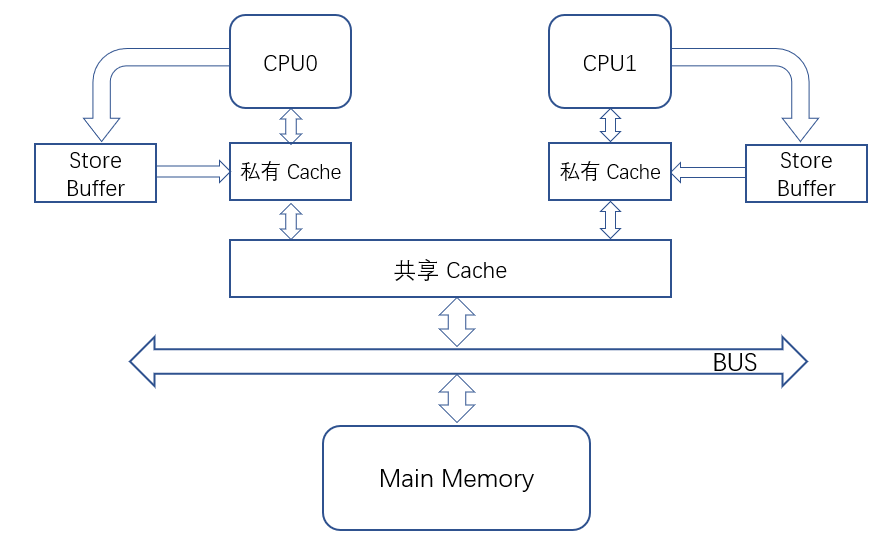
基于之前的缓存结构,增加完Store Buffer之后的结果如上图所示。
整个同步过程:CPU想要修改某个缓存数据,首先通过总线广播获得总线所有权,发出信号通知其它CPU需要将该缓存块数据置无效,然后将需要更新的数据放入到Store Buffer。而此时就可以释放总线所有权去做其它的事情不用等待收到ACK(效率提高在此),等其它cpu都收到再由Store Buffer慢慢做核间同步,刷入Cache的值即可
当CPU读数据时,首先会先在Store Buffer中查询记录是否存在,如果存在则会从写缓冲区中直接获取,这一机制即是 Store Fowarding。
失效队列 Invalid Queue
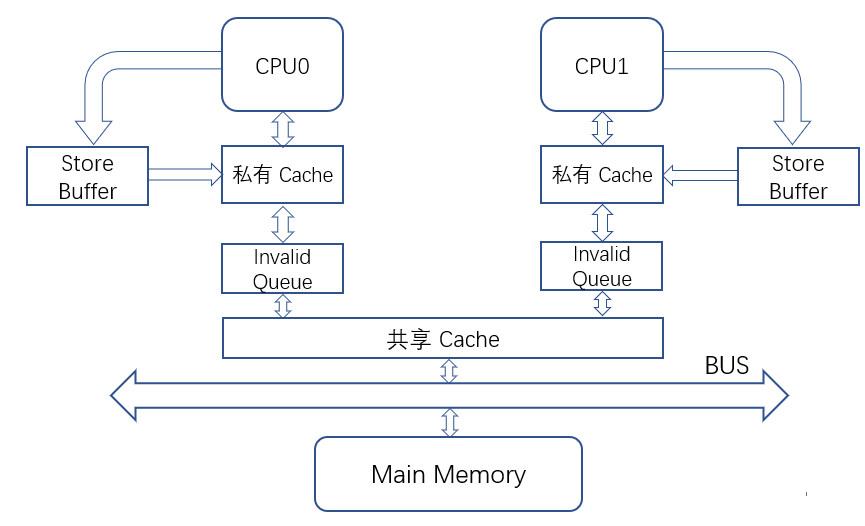
在Store Buffer基础之上,增加完Invalid Queue之后的结构如上图所示
失效队列的存在可以说是更好的使Store Buffer工作。当CPU收到使某个缓存行失效的请求时,如果迟迟不回复ACK则可能导致Store Buffer里数据越来越多最终溢出,因此Invalid Queue的存在可以说是为了平衡Store Buffer写入速度和收到ACK速度
过程:当CPU Core收到使某个cache失效的消息时,先回复确认收到的消息,然后将失效的数据加入到Invalidate Queue中。而队列的实失效的操作等待空闲时候在进行处理。
内存屏障
MESI优化之后带来的问题
MESI协议本身属于强一致性协议,但是经过性能的优化变成了弱一致性协议,这就导致在某些中间状态下多核CPU的数据可能并不一致。
Store Buffer
由于Store Buffer的引入将部分事务变成并行,这就将导致数据的更新顺序将不会严格按照代码顺序执行,进而导致其它CPU拿到正确数据的时机延后。例如:CPU需要顺序执行A、B两条写指令,A在CPU0的缓存行状态是S,B在CPU0的缓存行状态是E,最终的cache对于两条指令所对应的两个数据的更新的顺序可能不是我们所期望的
Invalid Queue
CPU1在回复ACK之后实际并没有对数据所在的缓存行置Invalid,而是放入到队列中。假如此刻CPU0更新了缓存行这将导致该数据在两个核的cache上表现不一致
Reorder
指令重排序从源头上就造成了指令实际执行的顺序与我们代码所期望执行的顺序存在差别。而Reorder设计的本质实际上是为了对我们的代码进行优化,提高cache命令率从而提高执行效率
- 编译器重排序
- CPU乱序执行
解决方案
其实对于以上MESI优化带来的问题归根结底是在多核CPU上导致最终结果的偏差。进一步思考是多核CPU同时修改同一个变量时而引发的问题,而在实际过程中这种情况是比较少的。在效率和极少数数据不正确两者的考量下,继续基于此进行优化,但是不是硬件优化而是通过软件由程序员保证数据的一致性。因此在需要核间的同步的情况下,多线程对于数据的修改和对于数据的使用需要引起注意,在适当的地方添加内存屏障
内存屏障(Memory Barriers)其实可以理解为一道墙,前面的读写操作没有完成后面的读写操作不能发生
读屏障
本质:读屏障前后指令的读操作不能翻越屏障!强制CPU在屏障前的读操作处理到所有Invalid Queue中的数据,获取到最新的数据。
写屏障
本质:写屏障前后指令的写操作不能翻阅屏障!强制CPU在屏障前的写操作清空Store Buffer内容,将数据更新至cache甚至主存
读写屏障
以上两种屏障只有在区分读写屏障的体系结构里才会有作用,比如 alpha 结构。而在 X86 和 Arm 中是没有作用的,这是因为 X86 采用的 TSO 模型不存在缓存一致性的问题,而 Arm 则是采用了另一种称为单向屏障的分类方式。
参考资料
- 缓存一致性硬核讲解
- 编程高必学的内存知识(极客时间 海纳)